PART 1: HOW MUCH IS YOUR DATA WORTH TO OTHERS?
The recent NSA spying sh*tstorm has demonstrated that our digital data matters. It is not just data, it is a digital representation of our physical selves. Our identity is both physical and now digital as well. Platforms such as Second Life offered us the possibility to spend time on the virtual side of this identity, or even create a new identity which we preferred over reality, but this concept never really caught on. Maybe it came too early, or people just didn’t want it. But Facebook, blogs, personal websites and the whole mess of social networking platforms show clearly that part of our identity is increasingly in a digital form.
What is your private data?
This identity consists of a whole soup of different types of information flotsam and jetsam which is your private data. Your private data (a.k.a. “personal data”) is any piece of information which documents any aspect of yourself. This could be bits of information which document your physical bag of meat, blood and bones: height, hair color, IQ, etc.. It may also contain information about your behavior, such as your workout routine, where you are, and so on. This behavior can also be online activity or consumer behavior, such as where you shop, what you buy, or which websites you routinely visit. Other types of information could be about your history, such as your education, life events, or moving house. You get the point: everything-and-anything.
From a more practical standpoint, NIST defines what they call “personally identifiable information” (PII). This is any information which can be used to identify you, either alone or in combination with other information. That is extremely broad. Even anonymous and seemingly innocuous pieces of information can be used to identify you when brought together. This happens when the combination of the anonymous information leads to a unique configuration, even if each piece is not unique. For example, the way you configure your browser is often unique enough to identify you, like a fingerprint. Don’t believe me? See for yourself! Furthermore, even a few simple hints can narrow you down fast. 87% of people in the US can be uniquely identified by gender, zip code and data of birth alone. So everything is private data, but in the U.S. there is almost no legislation with respect to what can and can’t be done with that data in the private sector. Parts of Europe have far more restrictive privacy laws, with the wealthier northern Europe leading the way.
How is your data created?
Any time you fill out an online form, open a webpage, sign up for something, or even just buy a product with a credit or debit card, you are creating your own digital footprint, or private data. Sometimes it’s for your own use, such as when you enter your height into the scale in your bathroom so it can calculate your BMI. Other times you entrust it to an online retailer when you create an account with them. In many instances, the fine print allows them to use it for marketing purposes, which may even include resale.
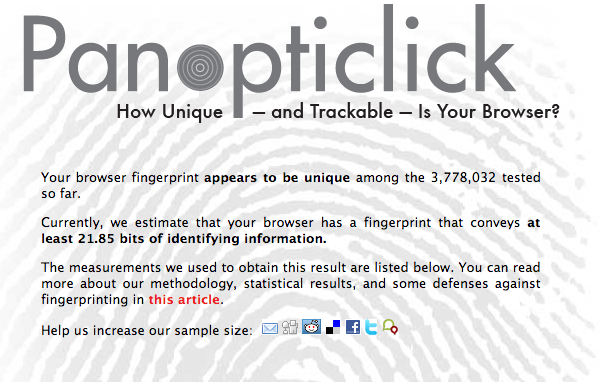
- https://panopticlick.eff.org/ shows you how unique your digital fingerprint is.
Loyalty programs are a great example of this, where for a small incentive, you provide the offering company with all the information they need to connect all your purchases to your name or ID. In some cases and countries, membership is not even needed and retailers can track you and create a profile using the card you used for payment. This allows them to improve their service to you, but also to find out all kinds of stuff about you as well. Sometimes it gets super creepy. For example the giant retailer Target figured out that a teenage girl was pregnant based on changes in her purchasing behavior and sent her some ads for baby paraphernalia. The urban legend goes that Target knew before she did which makes an awesome story, but it looks like in reality they figured out after she did but before daddy was clued in. He blew a gasket, thinking the retailer was encouraging rather curious behavior in his daughter. Severe awkwardness ensued.
Many online companies track your browsing behavior using so-called “beacons“. These are pieces of code within webpages that alert a central location that you have visited this page. And they are everywhere (if you don’t like it check out Ghostery). This is all legal. There are laws protecting what can and cannot be done with this data, although they are pretty weak in the States, especially when compared with Germany for example.
However, often times your personal data is collected or shared illegally. For instance, institutions which you have entrusted with your personal data can be hacked. Google the words “personal data leak hacked” and you’ll see how many examples of this there are. Hackers can then resell that data for a profit. Sometimes, large companies “inadvertently” collect data when they shouldn’t be, such as an LG TV which just happened to send home highly valuable viewer information even if you explicitly opted out. That’s right, they integrated the opt-out option and then ignored what you entered. Google Street View drove around collecting data from unencrypted WiFi networks all over the world “by accident” which got them in some serious hot water.
How much are people paying for and profiting from this data?
Data from a single individual is sold on the market for anywhere from less than a single cent up to around $5, depending on who you ask and the content of your data. The data is sold in batches containing data from multiple user, and although the price for a batch can be in the thousands of dollars, this boils down to very little per individual.

Interestingly enough, although the data is bought for peanuts, it is estimated that the value gained from this data is around $1,200 per individual, about 240,000 times more. This is a simple estimation based on the total revenue generated by internet advertising per year, divided by the number of internet users. I’m sure in reality it is not that simple and there are other factors at play here as well. Another take on the value of private data puts the total at $430bn (315bn EUR) for 2011 and projects an increase to $1.4tn (1tn EUR) by 2020 in Europe alone! Assuming 500m internet users in Europe in 2011, thats around $860 (630 EUR) per person. This begs the question, why the discrepancy between what it is worth and it’s price?
One reason is that your data is sold many many times, and not just once. I couldn’t find any data on how often one individual’s data is bought and sold a year, but it is probably a large number. The total amount of money payed for the data of a single person may therefore be a lot closer to $1,200 than suggested. The data is also gathered in many different seedy ways, and is therefore often incorrect, making it less valuable.
What decides the value of your data?
Your data also becomes more valuable if you have certain conditions, such as diabetes or ADHD. Also recent life events, or events in your immediate future, such as having a baby or getting divorced, can also increase how much your data is worth. Obviously, the more information about you which is available the more the set of all of your data is worth.
Aside from collection, sale and resale, there are also other ways to turn a profit using your data. Companies like Facebook, Google, Foursquare, use your data to target you with adds which are better suited to your needs and preferences. While it might sound creepy, from your point of view it just means that you like more of what you see when using their web services. Not so bad, is it? In essence, we are paying for the services provided by these companies with our private data.
How much of their profit is generated using your data is unclear. Facebook and Google make $5 and $20 per year per user respectively, some would argue that most or all of this is generated through user data. On the flip side, their wide reach and massive number of active users would not be worthless if they were not collecting user data.
The important thing to note is that while they make unfathomable amounts of money every year using personal data, they don’t make this money by selling it. Just the opposite, they go through great lengths to protect it. And they have good reason to. Their business is generated by the fact that users surrender their data in order to use the services provided by these companies. And the premise is that users will do this if the service is useful and if they trust the company offering it. These days most people know these companies are amassing a wealth of their personal data, and seem to be generally ok with it. Assumedly because they trust the web-giant powers that be not to betray them.
What does it all mean?
Your data is big bucks. But not for you. Your private data is acquired:
- in return for services rendered like social networking, email, cloud storage (remember the old saying “if you’re not paying for it, you’re the product”)
- in exchange for small rewards such as loyalty programs and cashback programs,
- through indirect monitoring via web beacons single-sign-ons,
- or illegal activities such as viruses and hacking of otherwise trustworthy sources.
This data was worth 315bn EUR revenue in 2011 in Europe alone, but almost none of that landed in the pockets of the people who owned that data originally. There are laws which protect private data with northern Europe leading the way. However, as long as people continue to give this data away willingly for almost nothing, it seems difficult to foresee any change in the near future.
And now in conclusion, I will make an outrageous statement based on loosely coupled facts taken completely out of context. If you are an active Facebook (or any other company with the same business plan) user, you can assume that they have amassed almost all of your data, either through you giving it to them directly, or their ability to infer it based on what you did give them. If your data is worth $860 to $1,200 a year, then that means your Facebook bill is $70 – $100 a month!!!
Does that seem worth it to you? Tune in to part two of this series where I will look at what your data is worth to you.
One final note. If these numbers are even approximately correct, then Facebook and Google are very inefficient at turning that value into profit ($5 and $20 per user per year respectively). Now…is that a good or a bad thing?